Platform Engineering
Platform Engineering endeavors to make executing any software application safe, easy, and reliable. It starts from the mindset that Information Technology (IT) has become unnecessarily complex in many organizations and presumes that logical options exist to minimize or eliminate many of those complexities. All we need to do is step back and return to the basics.
On a fundamental level, all software applications ultimately require at least two technologies to function: storage and compute. The compiled application code must exist in some form of storage and will need some type of compute to execute. All we need to do is abstract and generalize these concepts for our customers. If we accept and build off this premise, we may realize that many facets of an IT environment could probably be simplified. It’s just a matter of figuring out what to simplify. It also helps to understand and accept the fact that even snowflakes are not special or entirely unique, so odds are your environment isn’t either.
At first glance, the notion that we could generalize the entirety of one’s IT infrastructure might seem like a fantasy. The layers of complexity that exist in most organizations have built up over time and typically result from an accumulation of temporary trade-offs that long ago became permanent. Many of these layers continue to persist within organizations due to often unvalidated perceptions of complexity and/or frailty. The fear of change can easily prevent the most basic change.
Platform Engineering is also rooted in the idea that within any given organization, the odds are high that most custom software applications “look” like each other. As a general rule of thumb, most organizations typically develop software applications using a specific technology and usually adhere to rote deployment patterns. In organizations where these statements are mostly true, Platform Engineering practices could be exercised to help streamline processes, alleviate contentions, increase security, and generally improve our Consumers’ experiences.
Platform Engineering does not portend to solve every challenge for every organization. Organizations face a myriad of challenges, not all of which are technical. Additionally, Platform Engineering may not be applicable to all organizations either; some may be too small, while others may be too niche, specific, or culturally ingrained.
Platform Engineering is heavily influenced by other trends and methodologies commonly found in modern IT organizations, such as ITIL, The Twelve-Factor App, and DevOps.
Overview
This definition of Platform Engineering focuses on two primary concepts: Actors and the Applications they are responsible for. Actors within a given organization utilize the Platform to execute their software Applications, and our goal is to make it safe and easy for them to run those Applications.
Actors are all the people in an organization who interact with the Platform in some meaningful way. As a practice, Platform Engineering seeks to empower Actors to consume IT resources in the safest, most reliable way possible within the known constraints of an organization’s capabilities. Actors can be any person in an organization and are hardly limited to IT personnel.
Applications, on the other hand, are the “things” that run on the Platform. Whether they be custom, homegrown, greenfield, COTS, Cron Jobs, or cloud-native – it shouldn’t matter since they are all just Applications as far as the Platform is concerned. Applications are full of nuances, and each application seems to present a unique set of requirements that must be addressed to properly execute. Those requirements typically fall into one of a handful of categories, and this approach to Platform Engineering recognizes that fact. This definition of Platform Engineering defines 6 discrete layers of technical concern generally present when attempting to execute most Software Applications. Each layer, detailed below, is designed to address a specific area of concern and may not even be relevant to every single Application.
Platform Actors
The Platform exists to serve the needs of an organization. All organizations are comprised of people who could be titled, grouped, and organized in numerous ways. Rather than attempting to classify every possible title or role, we opted to group people into three distinct categories: Consumers, Engineers, and Auditors.
Platform Consumers
Platform Consumers are the people who leverage Platform resources to host one or more applications. A Platform Consumer could be any person in your organization and is hardly limited to development personnel.
Platform Engineers
Platform Engineers are the people responsible for maintaining the underlying components of the Platform. This group contains your traditional Server, Cloud, and Network Admins\Engineers and could also include the developers who maintain automation components and other templates and artifacts that abstract the backing infrastructure.
Platform Auditors
Platform Auditors ensure that all organizational policies are being followed. To uphold integrity, it is recommended that this group be wholly independent of the Engineering teams responsible for maintaining the Platform. The ideal makeup of this group would include representation from legal, finance, security, and architecture groups.
Defining the Platform
A Platform is very similar to a functioning greenhouse in that it offers the environment, conditions, and tools needed to plant and foster living things. Greenhouses can contain numerous different types of plants, all within the same confines, sharing common resources, and under the purview of an operator. The greenhouse provides everything needed to sustain a plant’s desired conditions. Some plants need minimal inputs to survive, while others are more delicate and exact. Given accepted constraints, the greenhouse should be flexible enough to accommodate the broadest set of conditions possible, allowing a more diverse collection of plants to grow.
In IT, a running application isn’t all that different from one of those plants living inside that greenhouse. An application needs an environment to live in, and that environment needs to provide the tools and resources required to keep the application running (e.g., alive).
The Platform, as defined here, is comprised of up to 6 discrete layers or areas of concern. Each layer addresses a specific technical aspect or function typically relevant when bringing an application online. This model encourages flexibility and acknowledges that different applications have different requirements and that all layers may not be relevant to all applications.
The following two diagrams outline the different layers present in this definition of Platform Engineering and utilize the plant analogy when describing the purpose or function of each respective layer.
Platform Layers
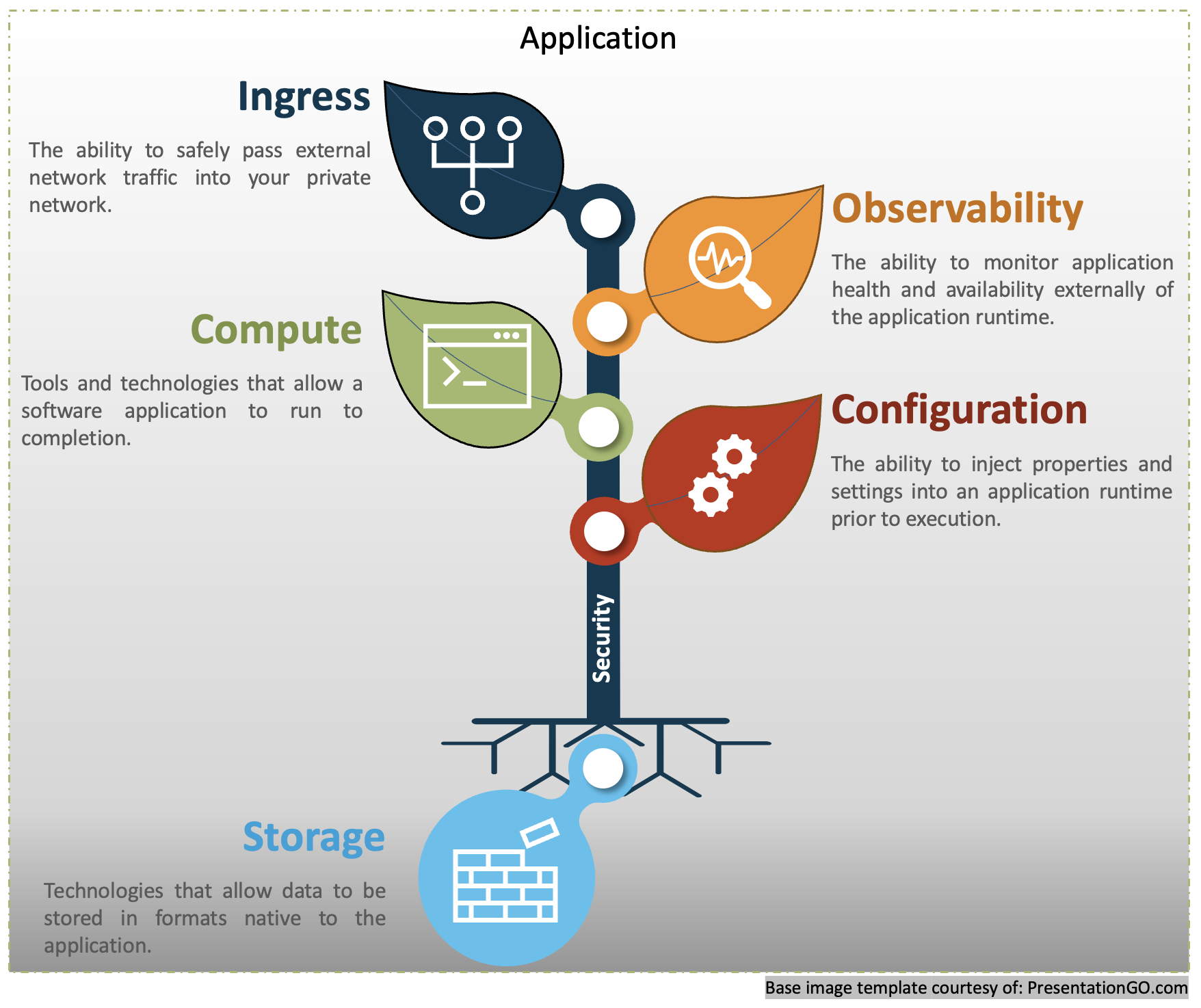
Platform Layers with Recoverability
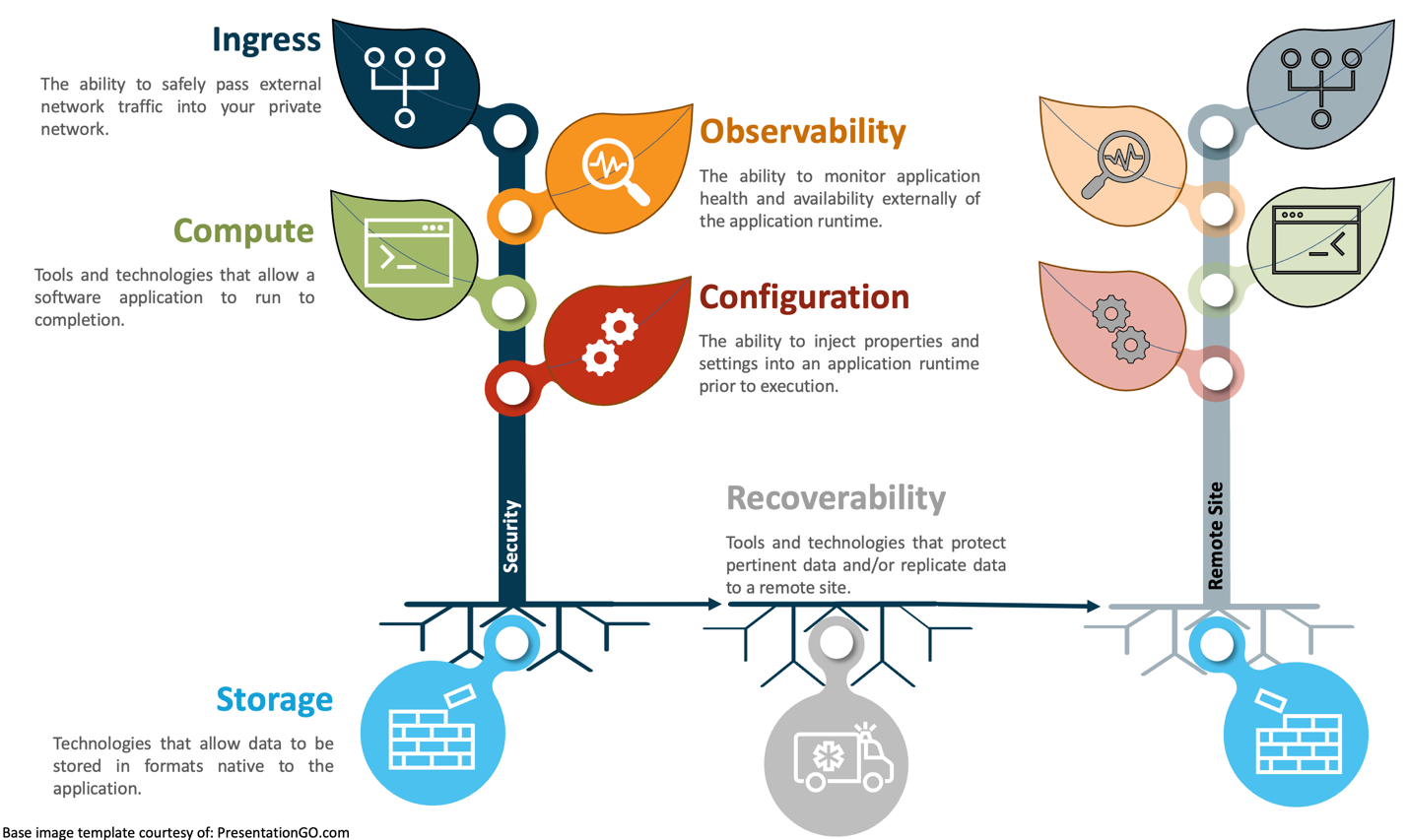
Platform Layers in Detail
Ingress
Overview
The Ingress “leaf” of the Platform Tree encompasses how network traffic is securely routed to a running application. This leaf concentrates on abstracting the configuration of Domain Name System (DNS), Secure Sockets layer (SSL), Firewalls, Proxies, Gateways, and other applicable components to a sufficient point that a new application can go live optimally without human intervention.
Technologies Employed
DNS, Firewall, Load Balancer, API Gateway, Certificate Authority
Personnel Involved
Network Engineers
Security Engineers
DevOps\DevSecOps Engineers
Guidance
Automating the Ingress leaf can prove challenging for some organizations. The core networking components, such as DNS, Proxies, or Firewalls, might be too old to support any automation options. While the ideal solution would be to upgrade these devices, that is not always a reality in every organization. In this case, a process should be defined to ensure related changes are put before responsible teams with an appropriate level of urgency and follow-through.
As a note of clarity, depending on your environment, the Ingress layer may also involve configuring applicable components to allow secure egress traffic.
Observability
Overview
The Observability leaf is centered on all matters of Runtime Inspection and includes any logs, metrics, telemetry, and other indicators that convey the health and availability of a given application.
Technologies Employed
Numerous technologies exist to support this layer, including Elasticsearch, Azure Monitor, Application Insights, X-Ray, Cloud Trace, Telegraf, Grafana, etc.
Personnel Involved
Application Engineer
Monitoring Engineer
Data Engineer
Data Visualization Engineer
Network Engineer
Guidance
Observability data should be considered localized and stored close to the resources it observes. This data is generally relevant on a site-by-site basis and usually only for defined periods of time. For example, if you have separate Production and Disaster Recovery (DR) sites, the Observability data collected in Production would have little real-time relevance when you fail over to your DR site. As such, it is recommended that you do not replicate your observability data between disparate sites; rather, keep it local to the site you are monitoring.
Applications should be externally diagnosable as much as possible, and this capability should be considered required, as reasonably as possible, of any new application being deployed to the platform.
The desire is to concentrate all Observability data into a single datastore and report on that data from one single tool, e.g., the single pane of glass. That outcome can be very difficult to achieve, considering the disparity of available monitoring solutions and the different ways live data is stored. When possible, efforts should always be made to keep working towards that goal.
Compute
Overview
The Compute leaf describes the runtime environment of an executing Application. This leaf allocates appropriate CPU, RAM, and storage resources and hosts the application’s runtime.
Technologies Employed
Numerous technologies are covered by this leaf, including physical servers, virtual machines, containers, Virtual Desktop Infrastructure (VDI), and function apps. Compute could also include some or all Software as a Service (SaaS) solutions consumed by your organization.
Personnel Involved
Server Admin
Virtualization Engineer
Guidance
TBD
Configuration
Overview
Configuration is considered a first-class citizen in Platform Engineering, especially within organizations that employ a multi-environment strategy.
Configuration encompasses all mechanisms every application utilizes to pass mutable properties into its runtime. The definition and maintenance of these properties should be separated from the codebase, externalized into a governed data store, and injected into a running environment as appropriate.
Technologies Employed
Azure App Configuration, AWS AppConfig, LaunchDarklytm, Jenkins, Azure DevOps, GitHub Actions, etc.
Personnel Involved
Application Developers
Business Analysts
Configuration Analyst
Guidance
Configuration should be completely defined before any application is deployed to any environment. Any parameter or variable defined in the application code that may change in the future should be considered a configuration entry and externalized appropriately.
Configuration changes should be versioned and auditable to provide traceability, improve recoverability, and minimize drift.
Attention should always be directed at protecting all sensitive values according to your organization’s internal controls. If no controls exist, they should be implemented as soon as possible. At no point should sensitive configuration settings be hard-coded into any asset that is stored in a version control system outside your organization’s complete control.
Sensitive values should be stored in a Secrets Management System. When considering what to store in your Secret Management System, use the following rule: store the value in the Secret Management System if there is any question or doubt. Existing Secret Management Systems should allow for direct integration with additional platform tooling to ensure seamless consumption.
Storage
Overview
Storage underpins all of Platform Engineering and focuses on ensuring reliable persistence of all data consumed or generated by any agent or consumer of the Platform. We say storage underpins all of Platform Engineering because all other layers either draw from or feed into the storage layer. Configuration draws from Storage, just like Ingress. Compute, and Observability can feed in just as much data as they draw back out.
Technologies Employed
Dynamic storage allocation relies on the abstraction of any underlying storage hardware and/or services. It is recommended that Storage Engineers provide storage pools that Platform Consumers can use for their respective needs. A goal of Storage Engineers should be to consolidate existing storage as much as possible to make recovery efforts easier.
Personnel Involved
Storage Engineer
Backup Engineer
Network Engineer
Guidance
Storage should be able to be allocated as needed, persisted redundantly, and relocated as warranted to ensure minimal disruption to pertinent processes. As warranted by enterprise policies, consideration should be given to performance requirements, cost, and security.
Data has gravity, and the more critical it is to your organization, the more it “weighs.” The heavier the data, the harder it can be to move around.
Data should be tiered as much as possible within your organization, with less critical data stored on cheaper storage.
Recoverability
Overview
Recoverability is focused on the technologies and processes that protect your organization’s pertinent data and allow live operations to be relocated to another site in the event of a localized outage. Recoverability includes all data backup and/or state replication technologies available to an organization.
Technologies Employed
Backup Technology
State Replication Technology
Block Replication Technology
Personnel Involved
Backup Engineer
Network Engineer
Guidance
Deploying any new protected resource should automatically configure the appropriate recoverability resources.